

For the fifth post of the Know Your YARA Rules series, we want to create a comprehensive manual for regular expressions that would improve your YARA rules.
Why is it so complicated?
When discussing regular expressions, we must first address the elephant in the room. Regular expressions can get complicated rather quickly, mainly because they often look like winners in obfuscation games rather than something meaningful. It does not help that there are lots of sources on the Internet that sometimes contradict each other. Some documentation will tell you that regular expressions can match your case, while other sources will tell you that this cannot be done. So, where is the truth?
The reason for this is that several implementations and standards of regular expressions, unfortunately, do not always produce the same results. The difference is mainly in extensions that allow us to describe a broader range of strings. However, some expressions you use in your JavaScript code do not necessarily work in YARA rules in the same way, and some constructs are not even supported in YARA.
In this blogpost, we will first cover the basics that are the same for all implementations. Then, we will describe some additional features that can differ based on the implementation.
The formal definition
In formal theory, we define regular expressions as the way to describe a set of strings – a language. The descriptive power of them is useful but limited. Let’s say we use only the letters a and b in our language (for simplification). Of course, you can match only one letter, so a or b. Then, you can use the following operators to create more complex expressions:
- Concatenation: ab – a is followed by b, as in string “ab”
- Alternation: a|b – we are matching a or b, as in strings “a”, or “b”
- Repetition: a* – letter a is repeated zero to infinity times, such as in strings “”, “a”, “aa”, “aaa”, …
And that is it. You can combine the operators, but there is a limit to what you can describe. For practical purposes, there are several extensions that make regular expressions more usable. There are two types of extensions. The first one creates a syntax sugar around the basic definition. There are flags that influence the whole pattern (such as i for case-insensitive matching), metacharacters, such as wildcard “.” that matches any character (in YARA, this excludes the new line character, unless used with flag s), or quantifiers such as {4,5}.
The second type breaks the definition of the regular expressions so you can describe strings you cannot describe with the basic version.
The most famous example of such strings is language described as a^nb^n, where the number of letters a is equal to the number of letters b and no letter b is in front of a. So, strings like ab, aaabbb, aaaaabbbbb,… With basic regular expressions, you can have a random number of letters a followed by some number of letters b, but there is no mechanism that would compare the occurrences of these two letters to ensure they are equal. The PCRE implementation, for example, supports so-called recursive patterns, creating surprisingly short expression: /^(a(?1)?b)$/.
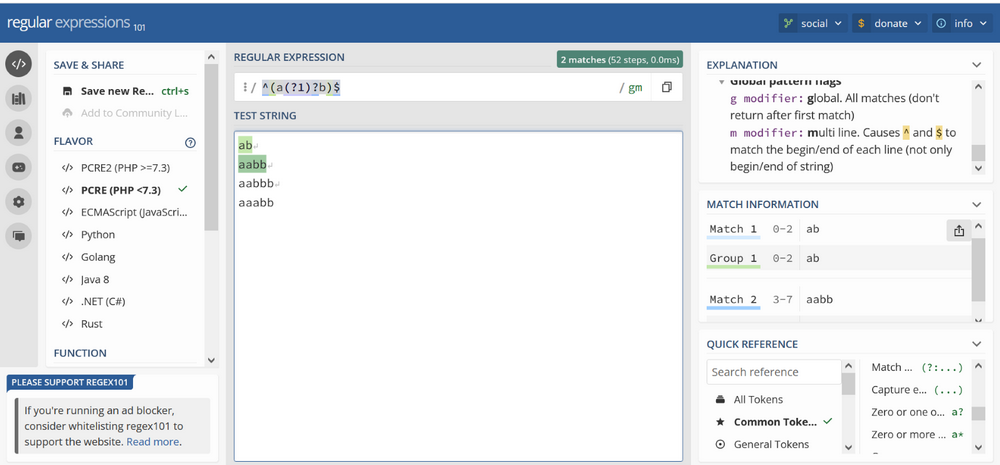
You can imagine the expression (?1) as a recursive function call that creates a new level of recursion while reading the letter a. After all letters a are read, we return from the recursion while reading the letter b. Only if the numbers of these letters are equal will we end with a successful match.

If someone tells you that this example can be matched by regular expressions, it depends on what kind of regular expressions they are talking about.
As YARA does not support these features, we will not include more details about the evaluation. If you want to learn more about this exciting topic, we recommend visiting www.regular-expressions.info website.
PCRE and other versions
There are many versions of the regular expressions, and navigating through them can be confusing. Let’s focus on the most important of them to keep it relatively simple.
If you use the grep tool, use the IEEE POSIX standard in the version of BRE (Basic Regular Expressions) or ERE (Extended Regular Expressions) when using the grep -E option. The only difference between these two is that in ERA, you do not need to escape metacharacters ( ) and { } in ERE, which are required in BRE.
PCRE (Perl Compatible Regular Expressions) extends these versions and is also a Perl library written in C. If you used regular expressions in the past, the implementation was most likely derived from PCRE or very similar. This version is so popular that it is the most used implementation standard. That is the reason why even YARA is based on PCRE.
Also note that there is the newest generation of the PCRE, PCRE2. There are some changes in syntax, but because YARA still uses PCRE, we will not go into details.
YARA world
As said before, YARA has an engine compatible with PCRE but with some limitations. The goal was to focus on the solution’s effectiveness, and for this reason, some extensions are not supported because they would slow down the rules. For the following summaries, we used the official documentation as source, which we recommend checking out as well.
Modifiers
For regular expressions, you can use modifiers nocase, ascii, wide, and fullword after their definition, changing the matching to case-insensitive, ascii form, wide form, and conditional delimitation by non-alphanumeric characters, respectively.
| nocase | case-insensitive mode |
| ascii | coding with one byte per character |
| wide | coding with two bytes per character |
| fullword | match only if delimited by non-alphanumeric characters |
Flags
YARA supports only two flags – //i for case-insensitive matching and //s for matching, where the dot symbols also cover new lines. Other flags are not supported, at least for now.
Metacharacters
| \ | quote (escape) the next metacharacter |
| ^ | match the beginning of the file or negates a character class when used as the first character after the opening bracket |
| $ | match the end of the file, or in the case of modules, it means the end of the string (we plan to create a special blog post about modules) |
| . | matches any single character except a newline character |
| | | alternation |
| () | grouping |
| [] | bracketed character class |
Classes
Classes, or character sets, are a listing of characters we want to match written in square brackets. We can write them individually, such as [abcd], or as a range, such as [a-d]. Note that [d-a] is an invalid range and leads to error. [d\-a] matches {a, d, -}, as well as [-ad] or [ad-] (if – is not in the middle of the class, it does not have to be escaped).
You can also combine notations, like in the example [0-9a-fxA-FX].
Sometimes, the list of characters you do not want to match is shorter and more readable. In that case, use the caret symbol (^) at the beginning of the class, like in example [^a-d] matching all characters except {a, b, c, d}.
Also, be careful while mixing upper and lower case characters. For example, [a-Z] is not a valid range as upper-case characters have lower ASCII values. You can use [A-z], but generally, it is better to write them as two ranges for more readable expressions: [A-Za-z].
Greedy quantifiers
With greedy quantifiers, we are trying to match the longest match possible.
| * | match 0 or more times |
| + | match 1 or more times |
| ? | match 0 or 1 times |
| {n} | match exactly n times |
| {n,} | match at least n times |
| {,m} | match at most m times |
| {n,m} | match n to m times |
Non-greedy quantifiers
With non-greedy (lazy) quantifiers, we are trying to match the shortest match possible.
| *? | match 0 or more times, non-greedy |
| +? | match 1 or more times, non-greedy |
| ?? | match 0 or 1 times, non-greedy |
| {n}? | match exactly n times, non-greedy |
| {n,}? | match at least n times, non-greedy |
| {,m}? | match at most m times, non-greedy |
| {n,m}? | match n to m times, non-greedy |
Escaped sequences
| \t | tab (HT, TAB) |
| \n | new line (LF, NL) |
| \r | return (CR) |
| \f | form feed (FF) |
| \a | alarm bell |
| \xNN | character whose ordinal number is the given hexadecimal number |
| \w | match a word character (alphanumeric plus “_”): [A-Za-z0-9_] |
| \W | match a non-word character: [^A-Za-z0-9_] |
| \s | match a whitespace character: [ \t\r\n\f] |
| \S | match a non-whitespace character: [^ \t\r\n\f] |
| \d | match a decimal digit character: [0-9] |
| \D | match a non-digit character: [^0-9] |
| \b | match a word boundary |
| \B | match except at a word boundary |
Word boundaries (in the form of \bpattern\b) allow us to match only “whole words”, meaning the match is surrounded by non-word characters or the start or end of the file. The negated version, \B, matches the pattern surrounded by word characters.
Tricky cases
. vs \.
A typical mistake is forgetting to escape metacharacters such as “(“, “)” or “.”, changing the meaning of the expressions. Be careful about these mistakes, as they can lead to false positives.
The situation is even more complicated when using square brackets to define the class you want (or don’t want) to match. In this scenario, the metacharacters are not usually escaped, but you need to escape a special character “-” if you are not using it as range and it is in the middle of the class.
* also means nothing
Sometimes, we need to express that the part of the strings is various lengths, and we use the star symbol for that. However, this also includes the empty string, which can lead to matching everything, such as an example /(malware|nonclean)*/.
.* vs .*?
When matching expressions without maximal length, there are two evaluation methods. The first one is called greedy, where we match the longest string possible. The second one is called non-greedy (or lazy) evaluation; in this case, we match the shortest string. For input Tomxxxx, /Tomx*/ will return Tomxxxx as greedy evaluation, while very similar regular expression /Tomx*?/ will return only Tom. In general, non-greedy evaluation is faster than greedy evaluation, but it is even better if you can specify the concrete numbers (such as {2,42}).
However, be careful when using these quantifiers in YARA. If the expression starts with them, YARA will match all versions of such strings. For example, for input xxxxTom and regular expression /.*Tom/ (or /.*?Tom/), YARA will find five matches: xxxxTom, xxxTom, xxTom, xTom, and Tom. That can easily lead to a warning about “too many matches” which invalidates the results. This behavior is YARA-specific because it uses the Aho-Corasick automaton. Other implementations, even if based on PCRE, may not have the same behavior and may return the longest match (xxxxTom) instead.
Not all quantifiers are treated equally
As we mentioned earlier, using a specific range in quantifiers (like {2,5}) rather than more general versions * and + is better.
There are two reasons why using format {x,y} is a good idea. Firstly, when you specify the minimal number of repetitions, YARA can use it for the Aho-Corasick automaton, which can improve the scanning speed (more information can be found in our first post [https://engineering.avast.io/know-your-yara-rules-series-1-know-your-yara/]). The second reason is that you are forcing a limit to the match and how many matches you can get from YARA. Using the examples from previous points, x{2,5}Tom will return three matches (xxxxTom, xxxTom, xxTom), while Tomx{2,5} will return only the longest match, Tomxxxx.
Match what you need, not what you want
It can be tempting to create complex regular expressions to match every possible variant of the search strings. However, be aware of this trap. In most cases, if you struggle to describe everything in one expression, it is a signal to take a step back and think about what needs to be matched. If some parts are too random, there is always an option to skip them. You can still match the string partially, maybe even with a simple text string. Regular expressions are not miracle remedies; sometimes, the simplest solution is the best.
Issues with non-ASCII characters
The situation with non-ASCII characters is complicated by itself, and in YARA, it is even more complicated. In the official documentation, you can find an explanation that YARA does not support non-ASCII characters in strings [https://github.com/VirusTotal/yara/wiki/Unicode-characters-in-YARA]. However, this is not entirely true because this decision was later partially reverted. You can now use either hexadecimal notation (such as \xD0\xAF for Я) or non-ASCII characters in strings and regular expressions, except classes. The classes do not currently support any form of non-ASCII characters.
rule test
{
strings:
$re1 = /ЯRA/ // This works fine
$re2 = /[a-Я]/ // This generates error
condition:
$re1 or $re2
}
error: rule "test" in rule.yar(5): invalid regular expression "$re2":
non-ascii character Code language: PHP (php)Additional sources
Regular-expressions.info
This fantastic website contains all the information about regular expressions you may want to know about. In addition, for great explanations about each (im)possible feature out there, there are also recommendations for other tools, tutorials, and books.
Regex 101
The website regex101.com is excellent for experimenting with regular expressions. You can write the regular expression and input you want to match, and it will highlight what was matched and why. You can also use so–called flavors – a type of implementation. We recommend using flavor PCRE for YARA rules and the preferred language for other cases.
There is also the Explanation section, where you can describe each part of your expression and what it does. This can be very helpful, mainly when debugging.
Conclusion
In this post, we investigated the slightly chaotic world of regular expressions. Hopefully, after reading this, you can navigate this world better and evade the traps across the road.
The main takeaways are:
- YARA’s regular expression engine is based on PCRE implementation; however, it does not contain special features like caption groups.
- Matching can differ based on the implementation and extension features. Be careful when copying regular expressions from the web or other applications because you can get different results.
- If you need clarification on what regular expression is describing (and believe me, you are not alone lost in the sea of bracelets and metacharacters!), try tools for visualization of matching, such as regex101.
And that is all for today! We wish you happy YARA rules writing!