
YARA is a language and tool used to describe and match detection patterns for malware classification. At Avast, we actively contribute to the development of YARA-based tools and libraries. Recently, we open-sourced our YARA Language Server and now open sourced YaraNG, a reinvention of the YARA scanner.
We run YARA at a big scale at Avast. Large rulesets (tens of thousands of rules) scan hundreds of millions of files in a single scan. YARA scanning at scale is not as easy as it sounds. You can look at it from two different points of views:
- You have an extensive set of files to scan
- You have a large ruleset that you need to scan with
Scanning extensive file sets across multiple machines/workers is straightforward, depending on the number of machines used to horizontally scale. A single file per server could be used, but is costly (and a little bit extreme).
Scanning with extensive rulesets is trickier. There are dependencies across rules, so just splitting your .yar file into multiple parts might not work right away. The more intertwined your rules are, the harder it is going to be. If you are able to do it, you can duplicate your file set, scan with different rules on each machine and then merge all the results together.
And then you might be in the same position as Avast, with a large ruleset and an extensive set of files to scan. In this case, you need to scale your fileset, but also scale your fileset shards and the ruleset shards. This can get expensive rather quickly.
At Avast, we decided to scale files but not rules. That left us with large rulesets, consisting of tens of thousands of rules. Using these rulesets, we noticed something most YARA users probably never have – YARA being CPU bound. Our disk controllers were not utilized to the maximum, while CPU was fully utilized.
On top of all of this, the YARA language standard is mostly centralized, as there is one reference implementation of the scanner dictating how the language evolves. Language defined by implementation is not a new concept, but having more options to choose your own scanner based on your needs while using the same language is useful. Imagine the same YARA language, but using it in various places, specialized for your needs, not limited by the single implementation of the scanner.
We started a little experiment, trying to address everything mentioned above.
Bottlenecks
It all started with the identification of bottlenecks. Where is YARA actually spending the most time during scanning? In order to identify bottlenecks, we ran YARA through perf and it eventually boiled down to these three bottlenecks:
- Execution of the bytecode
- Execution of the regular expression bytecode
- Aho-Corasick
Nothing unusual if you know how YARA works internally. YARA rule conditions are compiled into bytecode, which is then interpreted during the rule evaluation. The same applies for regular expressions with their own bytecode. Lastly, there’s Aho-Corasick, an algorithm for multi-pattern matching (matching multiple patterns during the single pass over the matched data). This algorithm efficiently matches the strings section of the rules. However, the algorithm is old and not suitable for modern architectures. Other shortcomings are described in our previous blogpost.
Closer look at the bytecode
The bytecode in YARA is simple. It consists of 117 instructions for regular bytecode and 26 instructions for regular expressions bytecode. The bytecode interpreter is a stack-based machine with a few slots for random-access memory, primarily used for loops and storing iteration count, the current iteration number, etc.
When YARA rules are compiled, bytecode is generated during a single pass and then it’s left as-is. Bytecode is not optimized (apart from very simplistic constant folding). We initially thought of introducing bytecode optimizations. However, we worried about the benefits, as we couldn’t identify major pain points and the optimizations YARA bytecode would benefit from.
At that time, we decided to take a step back and look at the whole picture. How many real instructions are executed for a simple rule with a few instructions? So we took this rule:
rule abc
{
strings:
$s01 = "abc"
condition:
$s01
}Code language: CSS (css)This gets compiled into these bytecode instructions:
INIT_RULE abc
PUSH $s01
FOUND
MATCH_RULECode language: PHP (php)The actual native code is executed with these four instructions (compiled with optimizations on Linux x64 machine, leaving out MATCH_RULE to make the comparison fair):
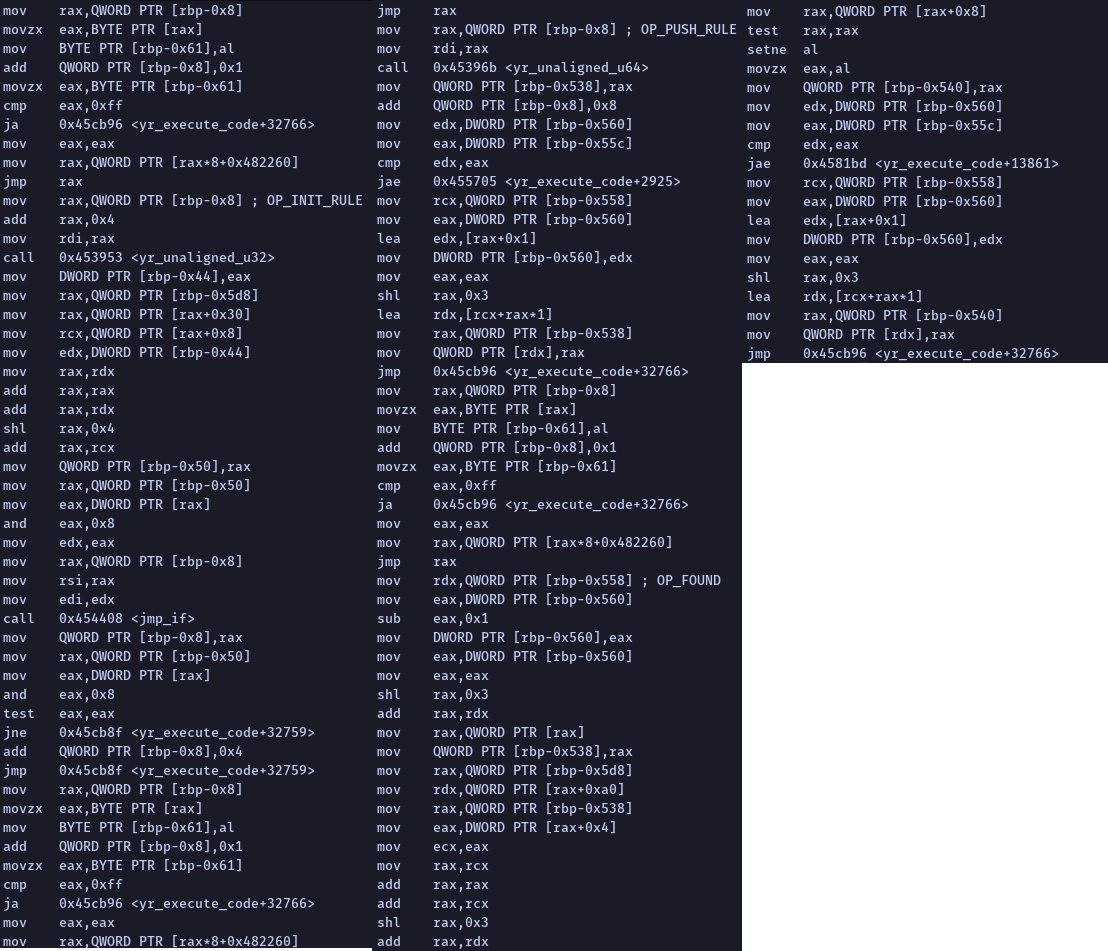
This is a simple rule. Imagine what it would look like if you started writing actual production-level rules. We asked ourselves, can we get rid of all of this? Can we somehow translate the YARA rules directly into the native code? And as it will be shown further in this blog post, we can.
Multi-pattern matching
Regular expression bytecode is heavily specialized for its purpose. The principles to address the regular bytecode bottleneck can be applied to regular expression bytecode, without building our own regular expression engine.
We were aware of HyperScan and that it performs well in the regex engine benchmarks. It is capable of multi-pattern matching and, compared to Aho-Corasick, it is well suited for modern processor architectures, utilizing SIMD instruction sets like SSE or AVX.
Dominika Regéciová performed a comparison of HyperScan vs YARA, proving it pays off. Therefore, we chose HyperScan as a solution, not only for regular expressions, but to replace the Aho-Corasick algorithm.
Compiler
We didn’t want to build a compiler toolchain ourselves (for example, with the help of the LLVM) as we would probably be still writing it instead of this blog post. We wanted to reuse existing tooling that is known to work. We know C++ the best from all the languages that are compiled to native code, so we decided to… (dramatic pause)… transpile YARA rules into C++.
The compiler is based on the yaramod library, our open-source library for the manipulation of YARA rules. In the first phase, it inspects the input ruleset and extracts the strings and regular expressions into the HyperScan pattern databases. HyperScan itself supports two different pattern types – literals, which contain no special metacharacters and ordinary regular expressions. Plain strings are mapped to literal patterns, while regular expressions are mapped to the regular expression pattern types. Special cases are hex strings, which are transformed into regular expressions, however, if we recognize that the hex string contains no special metacharacters (alternations, wildcards, jumps, …), we treat them like plain strings.
The second phase consists of transpling the condition of rules into C++ code, representing the same logic as in YARA. The transpiled ruleset is then compiled to the shared/dynamic library, which can be imported using the dlopen function.
Runtime
Even if YARA is transpiled to C++, logic capable of performing the YARA specific task of matching the strings at first, executing the condition of each rule, comparing string matches, etc, is required.
We therefore provide a common shared runtime that implements the two important things:
- Operational environment of YARA, bringing the concept of YARA rules into the whole compiled ruleset. It is capable of starting the YARA matching, recording the matches and handing the control flow to each rule for its evaluation.
- Common functions substitute YARA bytecode instructions, not used by the operational environment itself, but through the transpiled rulesets. Instead of generating a big snippet of code for an expression
$str at <offset>, we generate a call to a common functionmatch_at(), implemented in the runtime. Transpiled rule conditions are compact and easy to read.
To maximize compiler optimization efficiency, we heavily rely on the template metaprogramming in C++ to perform as many things as possible during the compilation time. The best example are the loops. Instead of using a generic template for all loops, requiring dynamic allocations, we generate a unique code for each loop in each depth.
Here’s an example of the transpiled form and compiled form of the rule shown in the beginning of this blog post (excluding the matching of course).
static bool rule_abc(const ScanContext* ctx) {
return match_string(ctx, 1ul);
}Code language: C++ (cpp)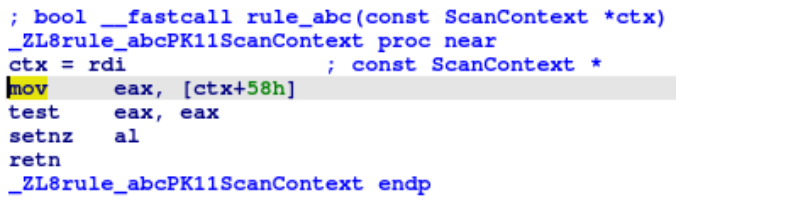
Here’s an example of a call to a built-in function that reads big-endian bytes on a low-endian machine. The compiler optimizes away our compile-time oriented runtime and directly compares the values against the big-endian form.
// YARA form
rule ints
{
condition:
int32be(0x200) == 0x41424344
}
// C++ form
static bool rule_ints(const ScanContext* ctx) {
return read_data<Endian::Big, std::int32_t>(ctx, 512ul) == 1094861636ul;
}Code language: C++ (cpp)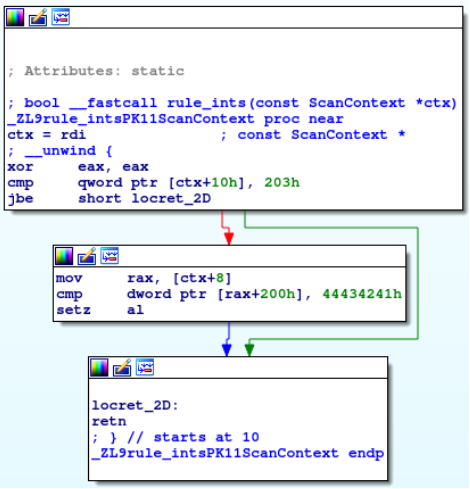
Putting it together
This is how the whole YaraNG toolchain looks like:.
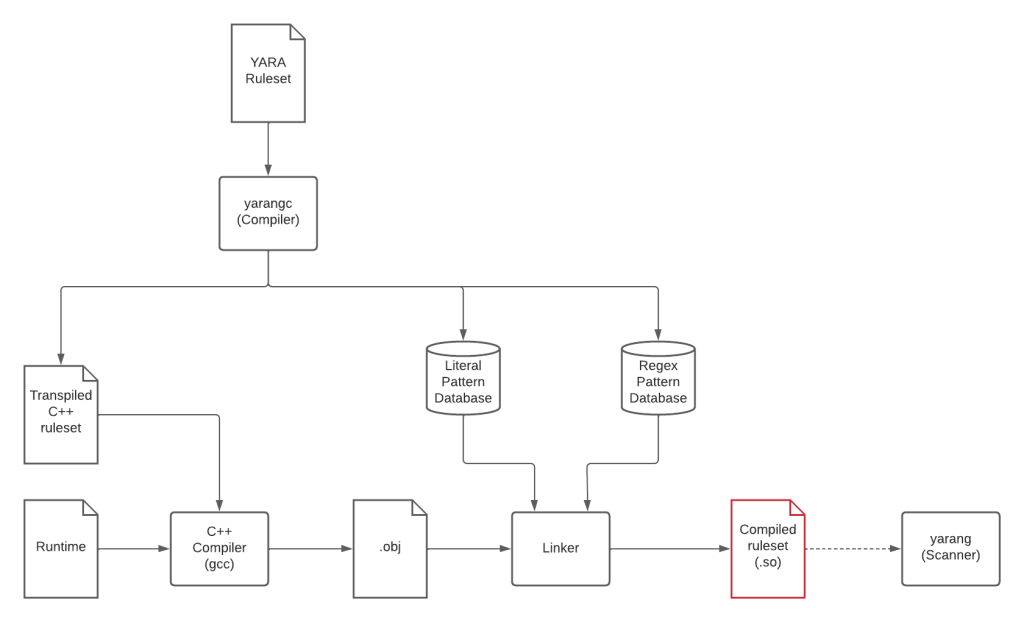
We provide two tools called yarangc, implementing the compiler, and yarang implementing the scanner capable of loading the compiled ruleset.
In the end, we achieved an improvement on our scanning hardware. Our regular scanner took around 20 minutes while the new scanner took around 13 minutes, which is a 35% improvement. Overall, CPU utilization was lowered, so with the new scanner, there was still headroom when it comes to the CPU utilization. Numbers from the time utility can be found in the README file in our repository.
Conclusion
We have shown that it is possible to take a different approach to YARA and that it might be possible to have multiple scanning tools over the YARA language in the future, depending on the needs of the user. In this blog post, we focused on the use-case of having faster scanning speed.
When considering a more distant future, despite disks usually being the bottleneck for now, NVMe SSDs are becoming more and more common on consumer machines. The throughput of the PCIe bus is also reaching speeds where we might not consider disks as bottlenecks anymore.
For now, only a limited subset of YARA language is supported, but with the help of the YARA community, this could become the alternative YARA scanner implementation. We made this project available on our GitHub where you can try to play around with it and even contribute. Let’s see what the future brings us!